th2k 超算使用教程
快速入门
在获取上机账号后, Linux\Mac 用户可通过命令行登录集群, Windows 用户则可以通过 ssh 客户端登录集群;登录集群后,编写作业脚本,并通过 sbatch 指令将作业提交到计算节点上执行;此外,集群上安装了常见的计算软件,通过module 指令导入计算环境。
先登录集群**,**登录前确保网络环境为内网 VPN
Linux\Mac 用户直接使用系统自带的终端通过ssh命令登录:
ssh user_name@ip_address -i /path/to/private_key
Window 用户可使用Xshell客户端进行登陆。下载Xshell,选择免费许可版,为了方便文件传输,可同时下载并安装 Xftp,安装完后点击软件左上角新建连接,输入IP和用户名,选择私钥文件即可登录;
登录后,编写作业脚本,并通过sbatch命令将作业提交到计算节点上执行。
假设我们的计算过程为:在计算节点上运行 hostname 指令,那么就可以这么编写作业脚本;
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=gpu_v100
#SBATCH -J myFirstJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
hostname
假设上面作业脚本的文件名为job.sh,通过以下命令提交:
sbatch job.sh
集群安装了常见的计算软件,可以通过module指令导入计算环境; 可以通过module加载平台上装有的软件环境,也可以自行安装配置需要的计算环境,下面的作业脚本加载了intel_parallel_studio/2017.1的软件环境,具体可用的软件环境可使用命令 module avail 指令进行查看。
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=C032M0128G
#SBATCH -J myFirstJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=2
module purge
module load intel_parallel_studio/2017.1
mpirun -n 2 hostname
连接集群
VPN 连接方式
从 Hillstone Secure Connect 下载最新版的支持 SSL VPN 功能的客户端,并使用 VPN 用户名与密码即可登录 VPN。
- 互联网客户端填写顺序如下:
- 服务器:vpn3.nscc-gz.cn或vpn1.nscc-gz.cn
- 端口号:4433
- 账号:VPN账号
- 密码:VPN密码
- 超算中心办公网和专线用户客户端填写顺序如下:
- 服务器:172.16.100.254
- 端口号:4433
- 账号:VPN账号
- 密码:VPN密码
- 中山大学校园网用户访问方法:
- 服务器:222.200.179.12或222.200.179.9
- 端口号:4433
- 账号:VPN账号
- 密码:VPN密码
Linux\Mac 登录和传输数据
Linux\Mac用户通过自带的命令行终端,以ssh的方式登录;
打开终端后通过以下命令连接,连接前请确保连接了 VPN
# user_name为上机账号,ip_address为所要连接集群的IP
ssh user_name@ip_address -i /path/to/private_key
通过 scp 或者 rsync 传输数据(需要带上 -i 选项)
scp [-r] file username@ip_address:~/
# 该命令将会把本地的名为file的文件上传到集群的home目录下,如果file是一个目录的话还需要加上参数r
scp [-r] username@ip_address:~/file ./
# 该命令将会把服务器上home目录下名为file的文件下载到本地当前文件夹下
rsync [-Pr] file username@ip_address:~/
# 该命令将会把本地的名为file的文件同步到集群的home目录下,如果file是一个目录的话还需要加上参数r
rsync [-Pr] username@ip_address:~/file ./
# 该命令将会把服务器上home目录下名为file的文件同步到本地当前文件夹下
Windows 用户使用客户端
Window s用户可以使用客户端登录集群、上传数据,常见的客户端有Xshell+Xftp,下载Xshell+Xftp时选择免费许可版,安装后通过以下方式登录集群;
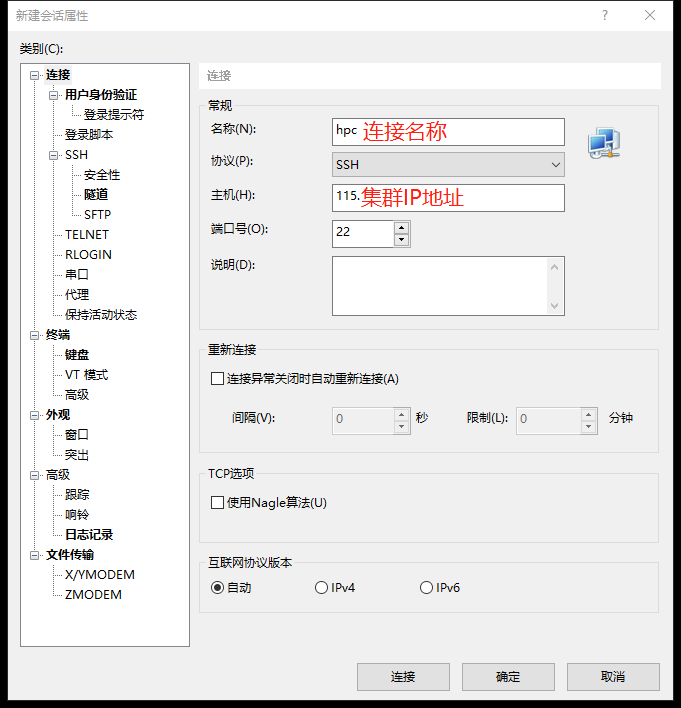 然后,点击用户身份验证,输入用户名,选择密钥文件,比如
然后,点击用户身份验证,输入用户名,选择密钥文件,比如 nsccgz_zgchen_2.id 登录;
下次登录集群时,点击"文件"»“打开”,找打对应的连接名称,选择连接即可。
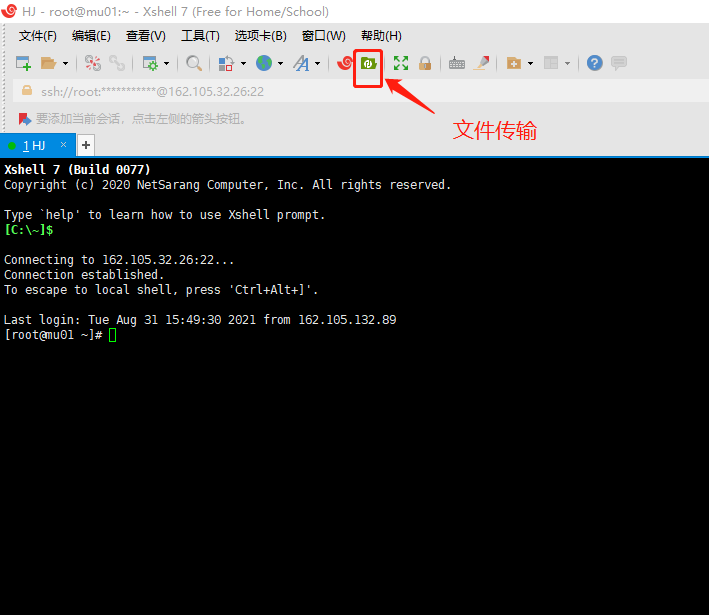
最后,登录后,在安装Xftp的前提下,打开文件传输按键,如下图所示;
提交作业
sbatch 提交作业
将整个计算过程,写到脚本中,通过 sbatch 指令提交到计算节点上执行;
先介绍一个简单的例子,随后介绍例子中涉及的参数,接着介绍 sbatch 其他一些常见参数,最后再介绍 GPU 和 MPI 跨节点作业案例。
首先是一个简单的例子;
假设我们的计算过程为:在计算节点上运行 hostname 指令,那么就可以这么编写作业脚本;
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH -p gpu_v100
#SBATCH --qos=low
#SBATCH -J myFirstJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
hostname
假设上面作业脚本的文件名为job.sh,通过以下命令提交:
sbatch job.sh
随后我们介绍脚本中涉及的参数;
-o job.%j.out # 脚本执行的输出将被保存在当job.%j.out文件下,%j表示作业号;
-p gpu_v100 # 作业提交的指定分区为 gpu_v100 ;
-J myFirstJob # 作业在调度系统中的作业名为myFirstJob;
--nodes=1 # 申请节点数为1,如果作业不能跨节点(MPI)运行, 申请的节点数应不超过1;
--ntasks-per-node=1 # 每个节点上运行一个任务,默认一情况下也可理解为每个节点使用一个核心,如果程序不支持多线程(如openmp),这个数不应该超过1;
通过以下命令或 yhi 可以查看集群分区的空闲状态;
sinfo
除此之外,还有一些常见的参数;
--help # 显示帮助信息;
-A <account> # 指定账户;
-D, --chdir=<directory> # 指定工作目录;
--get-user-env # 获取当前的环境变量;
--gres=<list> # 使用gpu这类资源,如申请两块gpu则--gres=gpu:2
-J, --job-name=<jobname> # 指定该作业的作业名;
--mail-type=<type> # 指定状态发生时,发送邮件通知,有效种类为(NONE, BEGIN, END, FAIL, REQUEUE, ALL);
--mail-user=<user> # 发送给指定邮箱;
-n, --ntasks=<number> # sbatch并不会执行任务,当需要申请相应的资源来运行脚本,默认情况下一个任务一个核心,--cpus-per-task参数可以修改该默认值;
-c, --cpus-per-task=<ncpus> # 每个任务所需要的核心数,默认为1;
--ntasks-per-node=<ntasks> # 每个节点的任务数,--ntasks参数的优先级高于该参数,如果使用--ntasks这个参数,那么将会变为每个节点最多运行的任务数;
-o, --output=<filename pattern> # 输出文件,作业脚本中的输出将会输出到该文件;
-p, --partition=<partition_names> # 将作业提交到对应分区;
-q, --qos=<qos> # 指定QOS;
-t, --time=<time> # 允许作业运行的最大时间
-w, --nodelist=<node name list> # 指定申请的节点;
-x, --exclude=<node name list> # 排除指定的节点;
接下来是一个GPU作业的例子;
假设我们想要申请一块GPU卡,并通过指令nvidia-smi来查看申请到GPU卡的信息,那么可以这么编写作业脚本;
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=gpu_v100
#SBATCH --qos=low
#SBATCH -J myFirstGPUJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=6
nvidia-smi
salloc 交互运行作业
申请计算节点,然后登录到申请到的计算节点上运行指令;
salloc 的参数与 sbatch 相同,该部分介绍一个简单的使用案例
一个简单的例子;
申请一个节点6个核心,并跳转到该节点上运行程序;
申请一个GPU节点,6个核心,并跳转到节点上运行程序;
salloc -p gpu_v100 -N1 -n6 -q low -t 24:00:00
# 假设申请成功后返回的作业号为2559148,申请到的节点是gpu5
ssh gpu5 # 登录到 gpu05 上调式作业
scancel 2559148 # 计算结束后结束任务
squeue -j 2559148 # 确保作业已经退出,也可以yhq命令
sinfo 查看资源空闲状态
通过sinfo可查询各分区节点的空闲状态;
首先介绍通过sinfo查看所有分区空闲状态;随后介绍通过sinfo查看指定分区的空闲状态;最后介绍sinfo的常用参数。
首先介绍通过sinfo查看所有分区的空闲状态;
显示集群的所有分区节点的空闲状态, idel 为空闲, mix 为节点部分核心可以使用, alloc 为已被占用;
随后介绍通过sinfo查看指定分区的空闲状态;
指定显示 gpu_v100分区的空闲状态
sinfo -p gpu_v100
最后是sinfo的一些常用参数。
--help # 显示sinfo命令的使用帮助信息;
-d # 查看集群中没有响应的节点;
-i <seconds> # 每隔相应的秒数,对输出的分区节点信息进行刷新
-n <name_list> # 显示指定节点的信息,如果指定多个节点的话用逗号隔开;
-N # 按每个节点一行的格式来显示信息;
-p # <partition> 显示指定分区的信息,如果指定多个分区的话用逗号隔开;
-r # 只显示响应的节点;
-R # 显示节点不正常工作的原因;
按照指定格式输出;
-o #<output_format> 显示指定的输出信息,指定的方式为%[[.]size]type,“.”表示右对齐,不加的话表示左对齐;size表示输出项的显示长度;type为需要显示的信息。可以指定显示的常见信息如下:
%a 是否可用状态
%A 以"allocated/idle"的格式来显示节点数,不要和"%t" or "%T"一起使用
%c 节点的核心数
%C “allocated/idle/other/total”格式显示核心总数
%D 节点总数
%E 节点不可用的原因
%m 每个节点的内存大小(单位为M)
%N 节点名
%O CPU负载
%P 分区名,作业默认分区带“*”
%r 只有root可以提交作业(yes/no)
%R 分区名
%t 节点状态(紧凑形式)
%T 节点的状态(扩展形式)
例:sinfo -o "%.15P %.5a %.10l %.6D %.6t %N"
squeue 查看任务队列
查看提交作业的排队情况;
这里介绍了几个使用案例,首先是显示队列中所有的作业;随后介绍如何显示队列中自己的作业;接着介绍如何按照自己的格式要求显示作业信息;最后介绍squeue的常见参数。
首先是显示队列中所有的作业;
squeue
随后介绍如何在队列中显示自己的作业;
# 注意whoami前后不是单引号
squeue -u `whoami`
接着介绍如何按照自己的格式要求显示队列信息;
squeue -o "%.18i %.9P %.12j %.12u %.12T %.12M %.16l %.6D %R" -u $USER
最后介绍squeue的常见参数;
--help # 显示squeue命令的使用帮助信息;
-A <account_list> # 显示指定账户下所有用户的作业,如果是多个账户的话用逗号隔开;
-i <seconds> # 每隔相应的秒数,对输出的作业信息进行刷新
-j <job_id_list> # 显示指定作业号的作业信息,如果是多个作业号的话用逗号隔开;
-n <name_list> # 显示指定节点上的作业信息,如果指定多个节点的话用逗号隔开;
-t <state_list> # 显示指定状态的作业信息,如果指定多个状态的话用逗号隔开;
-u <user_list> # 显示指定用户的作业信息,如果是多个用户的话用逗号隔开;
-w <hostlist> # 显示指定节点上运行的作业,如果是多个节点的话用逗号隔开;
按照指定输出格式输出:
-o <output_format> 显示指定的输出信息,指定的方式为%[[.]size]type,size表示输出项的显示长度,type为需要显示的信息。可以指定显示的常见信息如下;
%a 账户信息
%C 核心数
%D 节点数
%i 作业ID
%j 作业名
%l 作业时限
%P 分区
%q 优先级
%R 状态PD作业显示原因,状态R的作业显示节点
%T 状态
%u 用户
%M 已运行时间
# 例:squeue -o “%.18i %.9P %.12j %.12u %.12T %.12M %.16l %.6D %R”
sacct 查看作业相关信息
通过sacct和scontrol show job显示作业信息;
先介绍通过scontrol show job显示作业信息;随后介绍通过sacct显示作业信息;最后介绍通过saact按指定格式输出作业信息。
首先介绍通过scontrol show job显示作业信息;
scontrol show job 只能显示正在运行或者刚结束没多久的作业信息;
# 查看作业7454119的详细信息
scontrol show job 7454119
随后介绍通过sacct显示作业信息;
sacct -j 7454119
输出内容会包括,作业号,作业名,分区,计费账户,申请的CPU数量,状态,结束代码
JobID JobName Partition Account AllocCPUS State ExitCode
最后介绍如何通过sacct按照指定格式输出作业信息; 如下所示,指定输出内容为:作业号,作业名,分区,运行节点,申请核数,状态,作业结束时间;
format=jobid,jobname,partition,nodelist,alloccpus,state,end
sacct --format=$format -j 7454119
scancel 取消
取消队列中已提交的作业;
介绍几个使用使用案例,分别是,取消指定作业、取消自己上机账号上所有作业、取消自己上机账号上所有状态为PENDING的作业,最后介绍scancel常见的参数。
取消指定作业;
# 取消作业ID为123的作业
scancel 123
取消自己上机上号上所有作业;
# 注意whoami前后不是单引号
scancel -u `whoami`
取消自己上机账号上所有状态为PENDING的作业;
scancel -t PENDING -u `whoami`
scancel常见参数;
--help # 显示scancel命令的使用帮助信息;
-A <account> # 取消指定账户的作业,如果没有指定job_id,将取消所有;
-n <job_name> # 取消指定作业名的作业;
-p <partition_name> # 取消指定分区的作业;
-q <qos> # 取消指定qos的作业;
-t <job_state_name> # 取消指定作态的作业,"PENDING", "RUNNING" 或 "SUSPENDED";
-u <user_name> # 取消指定用户下的作业;
使用软件
通过 module 加载已有软件
软件安装到自定义的目录后,并不能直接使用,需要将软件的可执行文件路径等添加到对应的环境变量后才能使用。module则是一款环境变量管理工具,通过module实现软件环境变量的管理,快速加载和切换软件环境。集群安装了常用的一些软件和库,可通过module进行加载使用。
首先介绍module常见的一些指令;接着介绍几个module的几个使用案例;最后介绍如何编写modulefile来管理自己的软件环境。
首先介绍module常见的一些指令;
module help # 显示帮助信息
module avail # 显示已经安装的软件环境
module load # 导入相应的软件环境
module unload # 删除相应的软件环境
module list # 列出已经导入的软件环境
module purge # 清除所有已经导入的软件环境
module switch [mod1] mod2 # 删除mod1并导入mod2
接着介绍几个module的使用例子;
查看集群现有软件活库;
module avail
查看集群可用的matlab版本;
module avail matlab
导入matlab/R2017a软件环境;
module load matlab/R2017a
清除所有通过module导入的软件环境;
module purge
最后介绍如何编写modulefile来管理自己的软件环境。
自己编译安装的软件也可以通过module来进行管理,步骤为:先创建目录用来存放自己的modulefile;然后在创建好的目录下编写modulefile;
首先,创建目录用来存放自己的modulefile;
mkdir ${HOME}/mymodulefiles # 创建目录用于放自己的module file
echo "export MODULEPATH=${HOME}/mymodulefiles:\$MODULEPATH" >> ~/.bashrc
source ~/.bashrc # 或者退出重新登录即可
# 编写自己的第一个module file
cd ${HOME}/mymodulefiles
vim myfirstmodulefile
然后在创建好的目录下编写modulefile,假设在/share/home/test/soft/gcc/7.2.0安装了gcc编译器,则可以这么编写modulefile;
#%Module1.0
##
##
module-whatis "my first modulefile"
set topdir "/share/home/test/soft/gcc/7.2.0"
prepend-path PATH "${topdir}/bin"
prepend-path LIBRARY_PATH "${topdir}/lib"
prepend-path LD_LIBRARY_PATH "${topdir}/lib"
prepend-path LIBRARY_PATH "${topdir}/lib64"
prepend-path LD_LIBRARY_PATH "${topdir}/lib64"
prepend-path CPATH "${topdir}/include"
prepend-path CMAKE_PREFIX_PATH "${topdir}"
setenv CC "${topdir}/bin/gcc"
setenv CXX "${topdir}/bin/g++"
setenv FC "${topdir}/bin/gfortran"
setenv F77 "${topdir}/bin/gfortran"
setenv F90 "${topdir}/bin/gfortran"
编写好后执行module avail即可查看到刚刚写好的modulefile了 下为编写modulefile文件常见的语法;
set # 设置modulefile内部的变量
setenv # 设置环境变量
prepend-path # 效果类似于export PATH=xxx:$PATH
append-path # 效果类似export PATH=$PATH:xxx
Last updated 22 Nov 2023, 17:40 +0800 .